 Collected works and current thoughts
Collected works and current thoughts
Summary
When touching code that has a large or unknown number of consumers, start by adding rather than removing or changing.
Background
Imagine you have a mature code base that’s been in use for a decade. It is under active development, with multiple teams working in the code. While the code does not have a full suite of regression checks, though there are a number of automated checks that provide some idea of whether you’ve broken something.
Current development practices in this code base make continuous integration impossible, while this will change in the future, it is a reality now.
In this kind of situation, I’ve observed that developers will avoid refactoring because it’s likely that doing so will break the work of other people in other teams.
While we want to move to more frequent integration, and new code is better covered by automated checks, how can we safely change the structure of the code now, while we wait for the process changes to catch up?
Refactoring Databases
The book Refactoring Databases describes how to maintain a db schema over the life of a project. It introduces recipes for making schema changes in a way that allow for
- Zero downtime
- Evolutionary design
- Co-habitation
The recipes come in two varieties:
- Solutions where one client directly interacts with the database
- Solutions where multiple clients, on their own release cadence, interact with the same underlying database
The big difference here is that changes either might impact one group or many groups. When they might impact many groups, you either need to coordinate the work of multiple groups, or you need to find an alternative way of working.
The first option, coordinating the work is often called “big bang integration.” It is typically hard, error prone, and takes longer than anticipated.
What is an alternative way of working? At a high level, all changes start with the creation of something new rather than replacing something.
What does this look like?
Imagine you have a central class/function/module (the box containing circles below) used in several places:
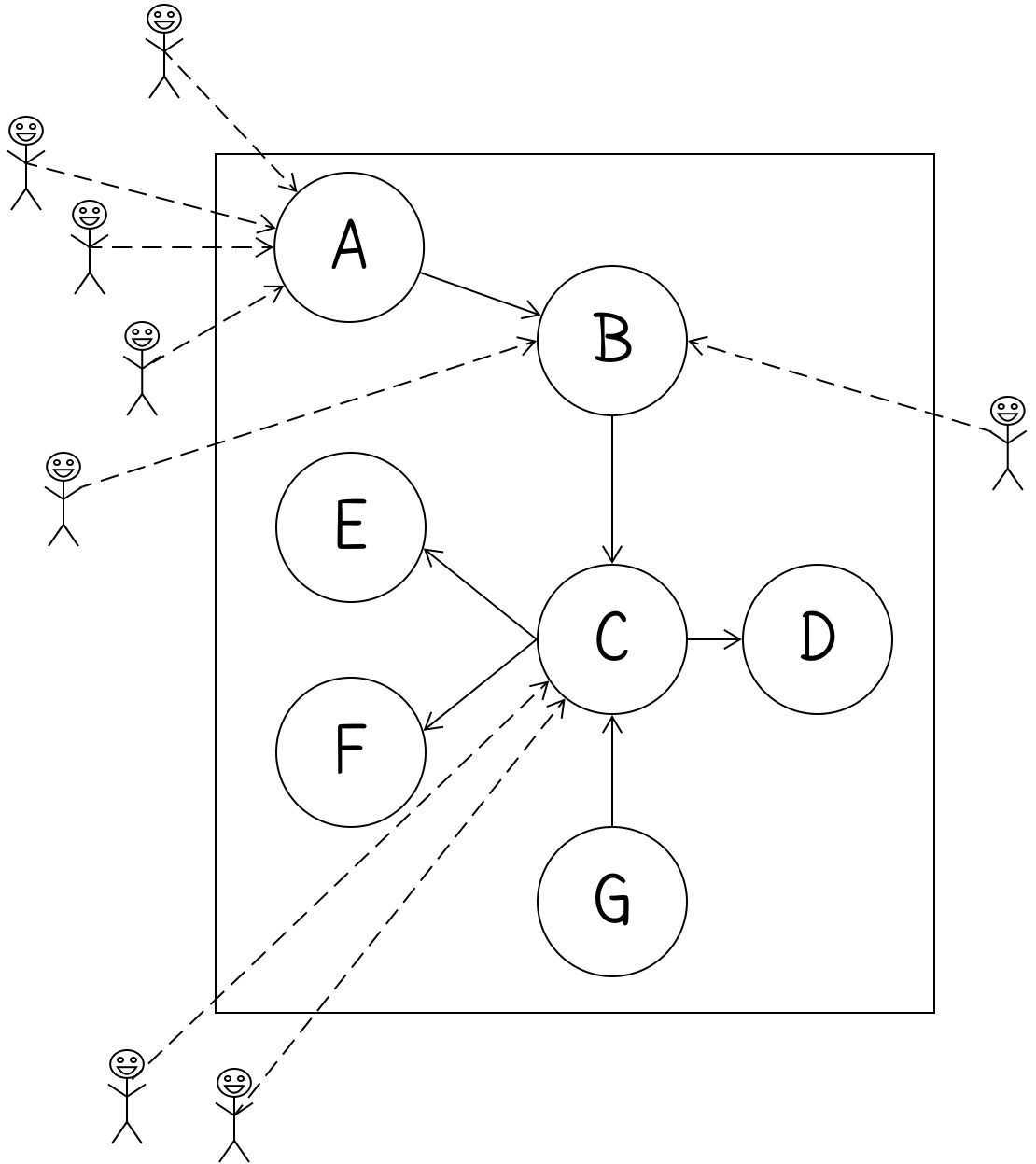
Let’s work through a few scenarios to see what options we have based on what we’re trying to do.
Scenario 1: Move something with no external clients
Suppose you need to make a change to the code in the circle labeled F. Further, suppose that the containing class makes that difficult, e.g., the class uses a library that requires a license server. It cannot be instantiated on a developer machine as they lack a license (real thing from another project, not made up).
I might do what Michael Feathers calls “sprout class.” As there are no external users, and few places where the code is used internally, this is a quick change that is likely safe:
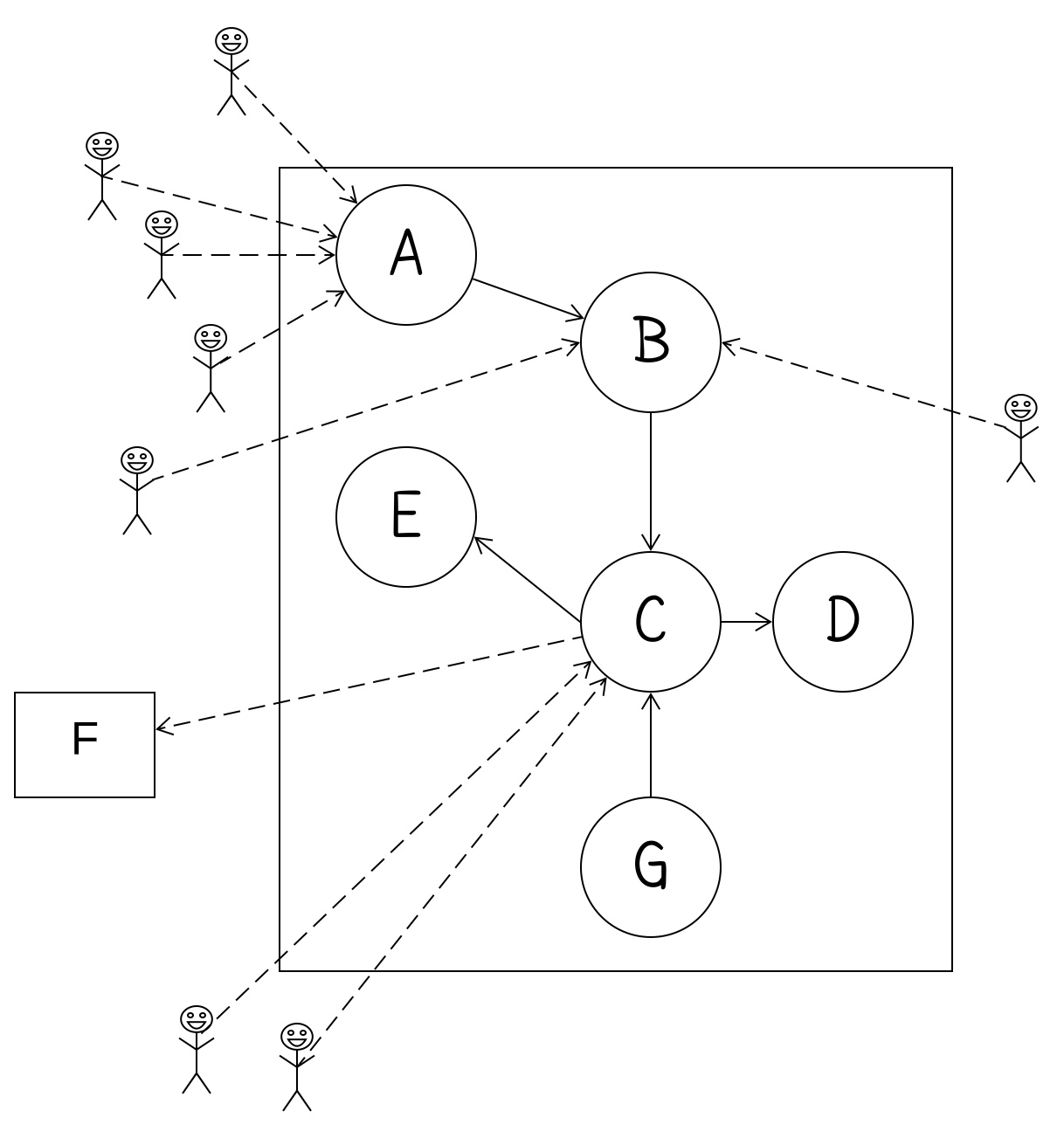
The code in the F circle becomes its own class and the one place where it was used in the original source now refers to this external class.
This allows quick improvement to F, simplifies the original class, and reduces the likelihood of merge conflicts.
This technique might, out of context, seem like the overall design is worse in that there are more classes. Also, this technique might make a class that is really just a function hiding in a class.
However, my definition of good enough is context dependent. Even if making F its own class is “worse” design in an overall sense, if doing so makes it possible/easier to get automated checks on code I need to change, the “worse” is in fact “better.”
Scenario 2: Moving something with external uses
Next, imagine you want to move the C circle instead. While in the original example there are four users of the code, two external, two internal. We can externalize the code and maintain backwards compatibility. Doing this allows us to increase the number of steps where the work is “stable.” By stable, I mean still compiles, and existing automated checks still pass.
The primary difference is what happens to the original method. In the first scenario, the method is fully moved into its own class and all code calling it, now calls a method on the new class. In this next approach, the original method still exists, but its implementation calls a method on the new class.
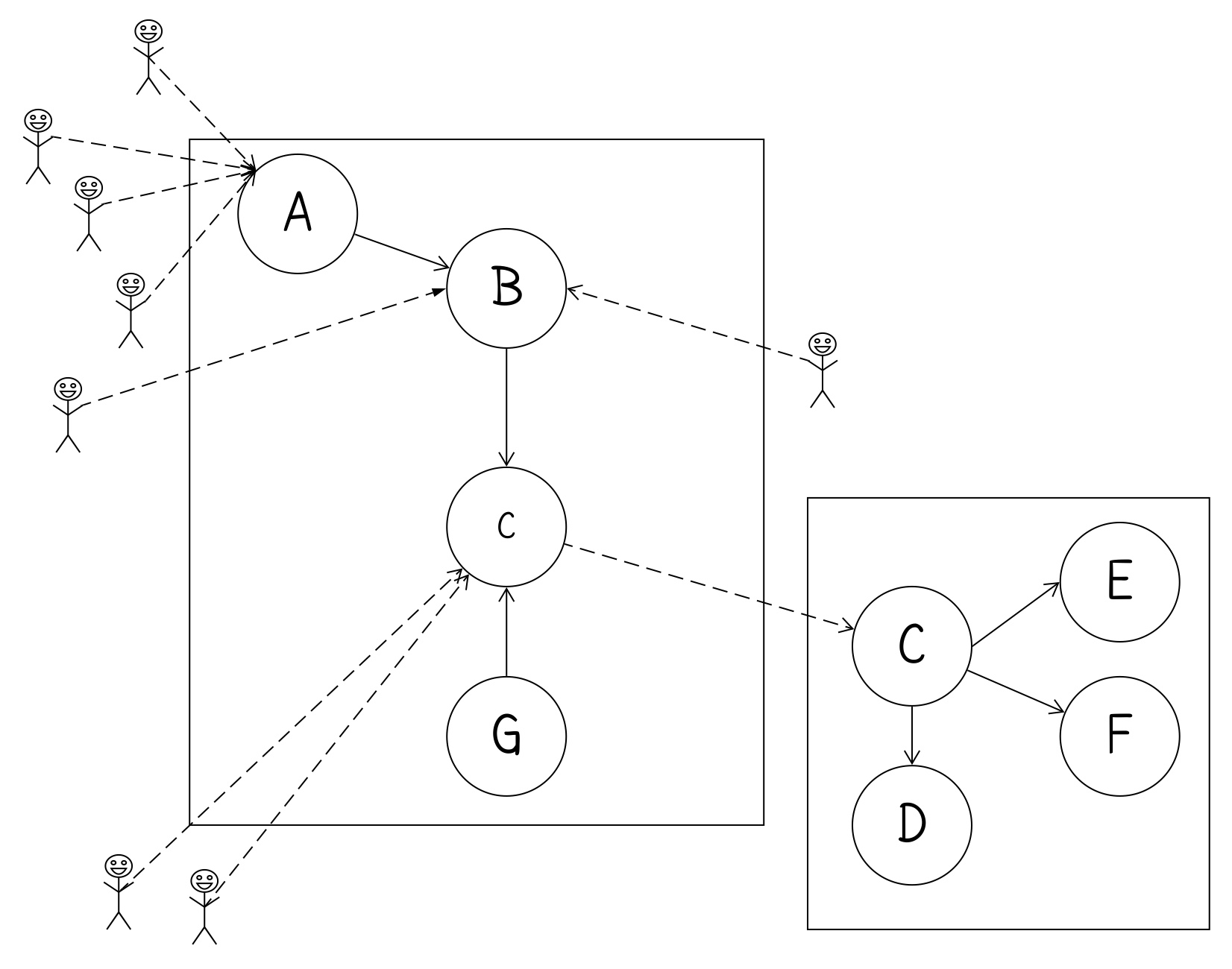
Notice that in this first version, we’ve created a new class that has the code from C and other code that only C used.
Rather than remove the original method, we instead have it call into the new class. This allows the code to be sprouted without having to change all callers. It makes the change smaller, less likely to involve merge conflicts, and I can safely do this kind of change in the absence of automated checks.
In this case, the next commit might be to update both clients and D to call out to C.
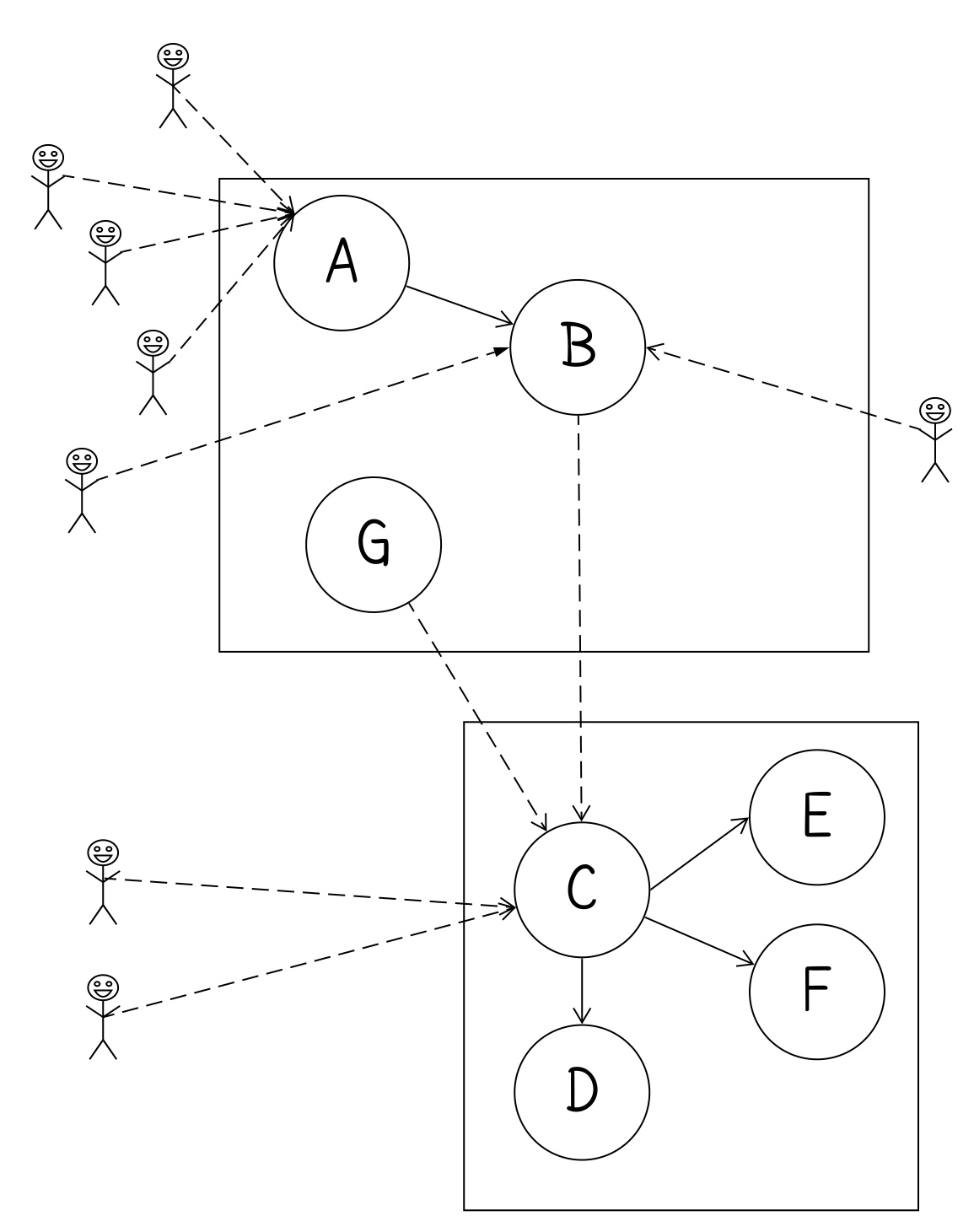
However, those 4 changes could each be their own commit.
If we do all of those changes in one commit, the commit is more likely to conflict with other changes simply because it is larger. So a larger number of smaller commits can make merging go more smoothly.
More importantly, if you are working on a class that happens to be an internally distributed library or used in other projects either as a binary dependency or even a source level dependency, or is invoked reflectively, it might be the case that you don’t know all of the code that touches the original method.
Without a clear understanding of the code base, I can probably make the first change, sprouting the class, safely. I might never make the next step, moving all references to the internal version to the externalized version.
However, irrespective of changing all the references, the first version with the original method calling out gives enough wiggle room to get what I’m touching now under automated checks. If I never make the global update of all calls, it’s OK.
The First Step
The simple idea underlying this approach is that the first step is creational, not destructive. Rather than killing the original method, which forces all clients to change, keep it in place, but it now delegates its implementation.
This is protected variation. The original method remains in place, protecting existing consumers from having to change. The underlying implementation delegates to the new implementation, providing a single path of execution. If there’s a need to eventually update all the client code, you can do it incrementally.
Since the required change can be done quickly, safely, and often with automated refactorings, it can get merged into master sooner rather than later. This allows us to make “big” changes in terms of getting work under automated checks, and even significant redesign. However, we can do it in a way that allows for quick turn around back to “green” that we can merge to master frequently.
